
Today, the Turing team is excited to go into detail on how Turing Bletchley v3, a new multilingual vision-language foundation model, is used across Microsoft products. This model is the latest version of Turing Bletchley – our series of multilingual multimodal foundation models which understand more than 90 languages. About two years ago we introduced Turing Bletchley v1 to the world via our blog post. Turing Bletchley v1 was among the first multilingual vision-language models – importantly these allow performant image search in both popular and low-resource languages. Since then, we have iterated on datasets, modeling, and pretraining to improve all aspects of our model, with the end goal of providing better search capabilities across languages. Last fall we released Turing Bletchley v3 internally, and it has now shipped in multiple products across Microsoft. You might already be using Turing Bletchley v3 when searching in Bing, and in this post, we will share more details regarding the model which powers the next-generation of multimodal and multilingual scenarios at Microsoft.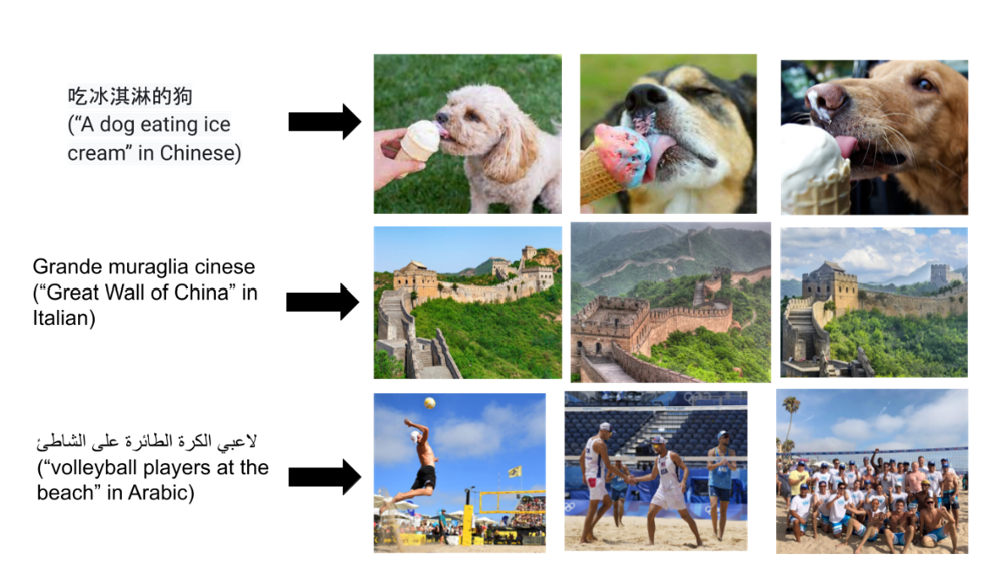
Turing Bletchley v3 enables performant image search across more than 90 languages
What is a vision-language model?
Humans use multiple senses for understanding the world – vision, hearing, taste, and so on. Vision language models are models which have two such “senses” – vision and language. More concretely, the model can take as input both images and text. Turing Bletchley v3 is a vision-language model which takes as input either an image or a snippet of text and outputs a vector – a location in some high-dimensional space. The goal is to have the locations corresponding to an image I and a text snippet J be “close” to each other if the image I and text J are semantically related. For example, we would want the locations described by the text snippet “a cat in a field of grass” to be “close” to images of cats in grass. These types of models can be used for example in image search – the vector of the user query is simply compared to the vector of all images in your database.
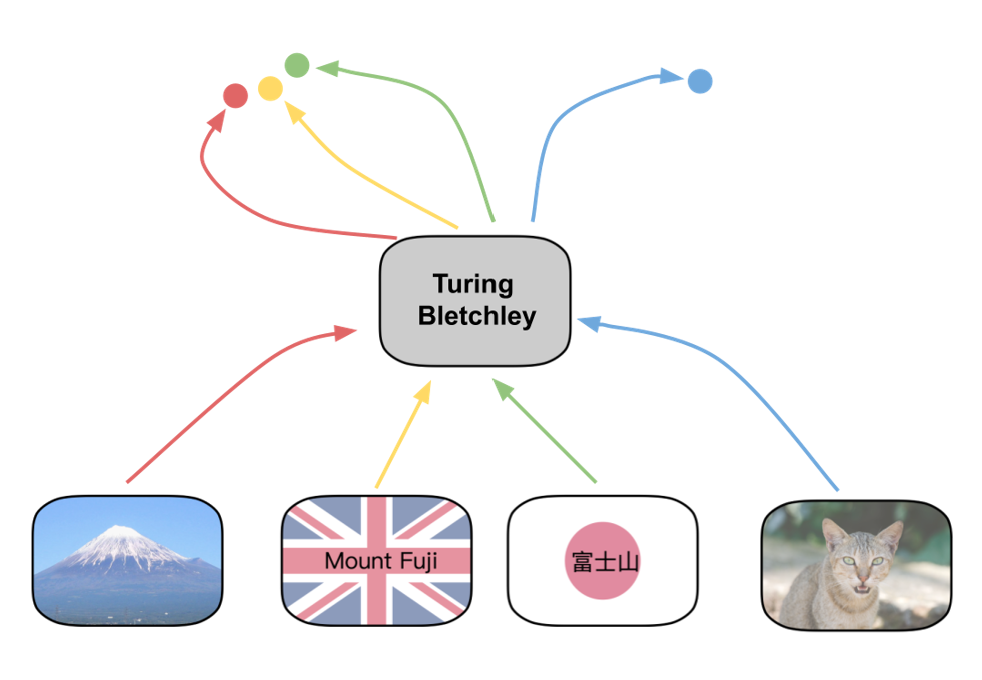
A vision-language model like Turing Bletchley can take either images or text and embed them as points in a vector space. Embedded sentence like “Mount Fuji” or “富士山” (Mount Fuji in Japanese) will be close to embedded images Mount Fuji in this vector space.
Pretraining
One technique that significantly improves Turing Bletchley v3 compared to v1 is the use of masked multimodal learning. This is a new training paradigm developed collaboratively by the Turing team and MSRA to empower efficient multimodal learning, and the paper describing this method was recently presented at CVPR 2023. Given an image and a caption describing the image, some words in the caption are masked. A neural network is then trained to predict the hidden words conditioned on both the image and the text. The task can also be flipped to mask out pixels instead of words. This type of masked training together with a large transformer-based model leads to a strong pre-trained model which can be finetuned on a diverse set of downstream tasks. When evaluated on several English-only vision language tasks this strategy reaches a new SOTA in many of them. We improved the SOTA for the NLVR vision-language reasoning task by more than 5 points and achieved a new SOTA for object detection on COCO – the first time a pure vision-transformer model topped the leaderboard.
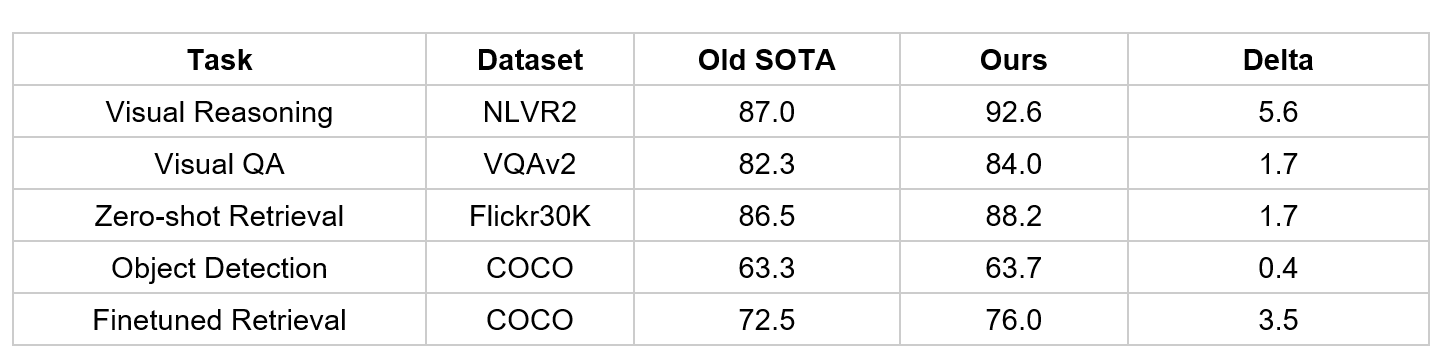
Masked pretraining improves upon the state-of-the-art (SOTA) vision language models on multiple tasks with a significant margin.
Most Microsoft products are served worldwide, e.g., Bing has millions of users spread over more than 100 countries. To serve this diverse demographic, Turing Bletchley v3 needs to be multilingual. The production model is thus trained in two stages on multilingual data. First a mask-based training stage using both image-caption pairs and text pairs where the same sentence is given in two different languages. Then a contrastive training stage which also uses translated language pairs. The resulting Turing Bletchley v3 model has strong zero-shot image and text capabilities in up to 94 languages, where we have balanced the performance of public academic benchmarks and internal production benchmarks. There are multiple evaluation benchmarks for multilingual and multimodal models, we have used an internal version of WIT – which relies on images and captions from Wikipedia. The WIT dataset contains many languages and allows us to assess the performance of Turing Bletchley across many low-resource languages. As can be seen, Turing Bletchley v3 gives strong improvements for both image and text retrieval. V3 gave significant improvements over v2, and hence we skipped productionizing Turing Bletchley v2.
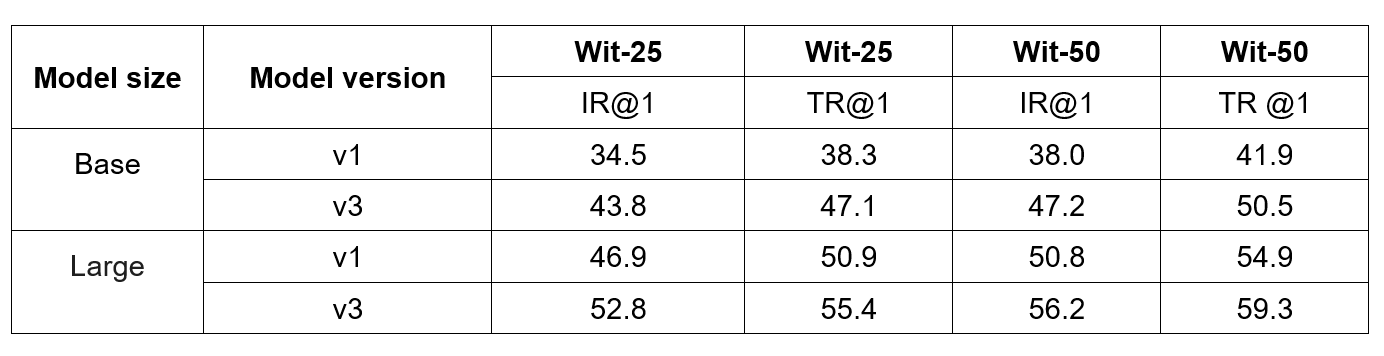 Evaluation on the WIT dataset from Wikipedia. We stratify the scores by image retrieval (IR) and text retrieval (TR) for the top 25 and top 50 languages. Turing Bletchley v3 shows strong improvements on multilingual retrieval over Turing Bletchley v1.
Evaluation on the WIT dataset from Wikipedia. We stratify the scores by image retrieval (IR) and text retrieval (TR) for the top 25 and top 50 languages. Turing Bletchley v3 shows strong improvements on multilingual retrieval over Turing Bletchley v1.
Images for Question-Answering
Question-and-answering is a feature in Bing where the user gets a direct answer in addition to links to external websites. In addition to showing text in this section, we show relevant images to delight our users. When judged by humans, Turing Bletchley v3 improves an internal quality metric that measures the relevance of the images to the query and answer pairs by 9 points for this scenario.
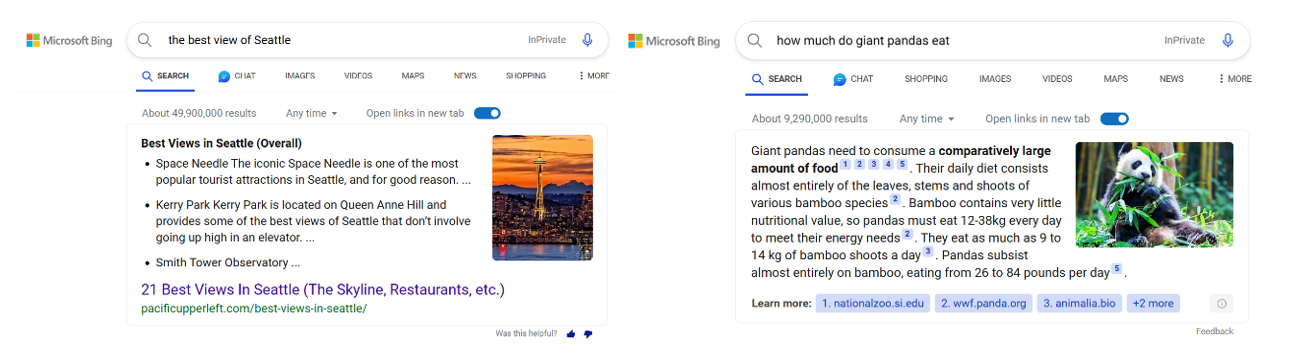
Two examples of images retrieved when answering questions on Bing. Both images are closely associated with the user query and the displayed passage: showing a panda eating and a scenic view of Seattle’s space needle.
Image Search in Bing
A very natural application of vision-language models is image search, i.e., given a user query or image, retrieve the most relevant image to show to the user. A distilled version of Bletchley v3 can be used in two such image search scenarios in Bing – image-to-image search and text-to-image search. 1) In the former case the user might have access to an image, and Bing retrieves similar and relevant images. After using the new vision-language model, user engagement (measured via clicks) increases by more than 6%. 2) In the latter case the user inputs a short text query and expects relevant images to be shown. Here we see an improvement of about 0.76 Discounted Cumulative Gain (DCG), a common metric used for measuring retrieval quality.
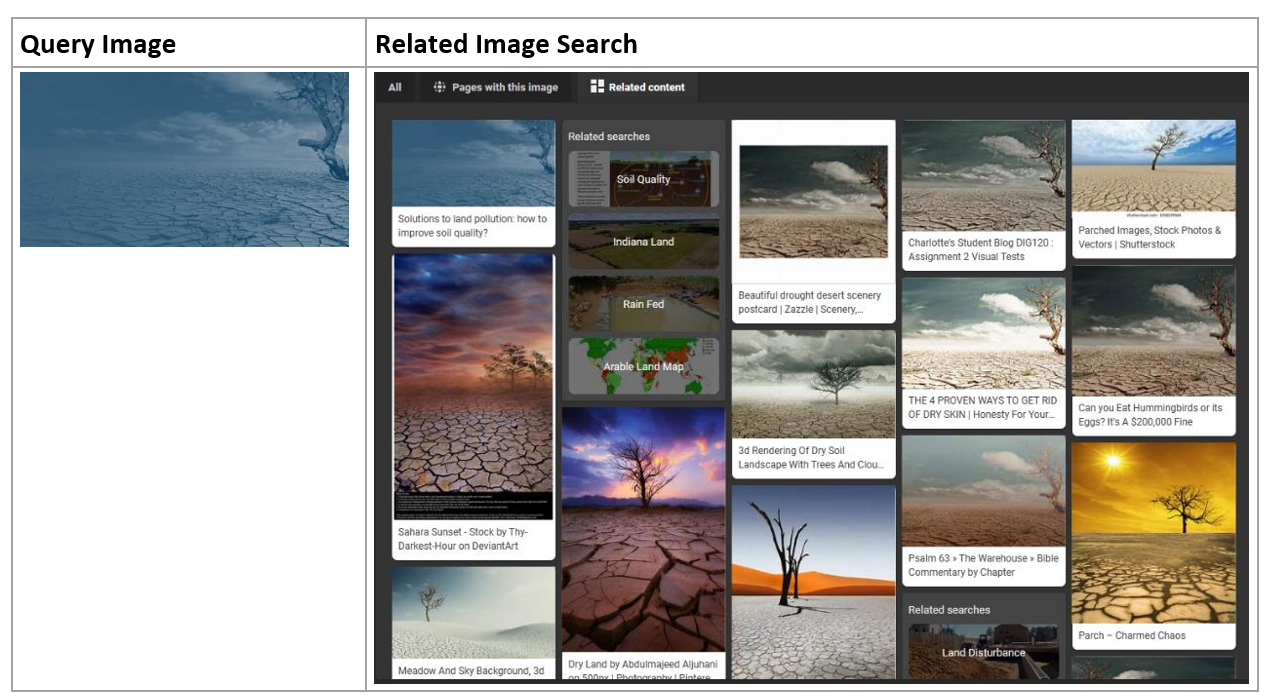
Example of image-to-image search. Given the image to the left, depicting dry and cracked earth, we can retrieve and show the images to the right. They all contain dry and cracked earth.
Content moderation for Xbox
Xbox uses automation to support player safety. The Xbox platform encourages players to be themselves and personalize their profiles, which includes uploading photos and images to their profiles; however, these photos and images cannot come at the expense of other players’ positive experiences. To ensure that only appropriate content is shown to the player base, the Xbox team implements various content moderation strategies including both human and automated methods. One such method is automatically identifying inappropriate images with machine learning models. Turing Bletchley is powering the latest version of the Xbox content moderation system, using its world knowledge to understand the many nuances for what images are acceptable based on the Community Standards on the Xbox platform.
