
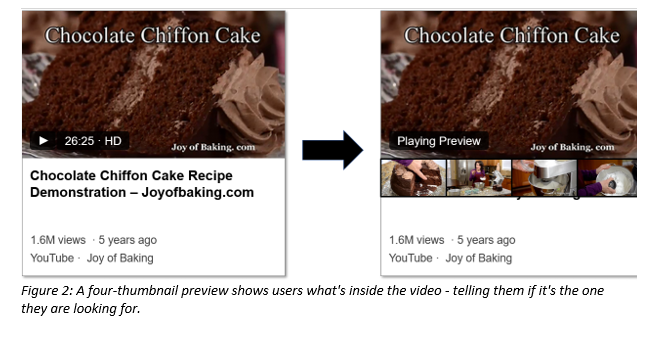
Videos account for some of the richest and most delightful content on the web. But it can be difficult to tell which cat video is really going to make you LOL. That can be a frustrating and time-consuming process and it’s why we decided to help by building a smart preview feature to improve our search results and help our users more effectively find videos on the web. The idea is simple – you can hover on a video-result thumbnail and see a short preview of the video which tells you whether the video is the one you are looking for. You can try this out with a query on the video vertical – like funny cats.
The concept may be simple, but the execution is not. Video summarization is among the hardest technical challenges. Things that are intuitive to human beings like “the main scene” are inherently case-dependent and difficult for machines to internalize or generalize. Here’s how we use data and some machine learning magic to solve this technically challenging problem.
Overview
There are broadly two approaches towards video summarization: static and dynamic. Static summarization techniques try to find the important frames (images) from different parts of the video and splice them together in a kind of story-board. Dynamic summarization techniques divide the video into small video segments/chunks and try to select and combine the important segments/chunks to create a fixed-duration summary.
We chose the static approach for reasons of efficiency and utility. We had data indicating that over 80% of the viewers hovered on the thumbnail for less than 10 seconds (i.e. users don’t have the patience to watch long previews). We therefore thought, it would be useful to provide a set of four diverse thumbnails that could summarize the video at a single glance. There were UX constraints that kept us from adding too many thumbnails. In this way, our problem became selecting the most relevant thumbnail (hereinafter referred to as ‘primary thumbnail’) and selecting the four-thumbnail set to summarize a video.
Step One: Selecting the primary thumbnail
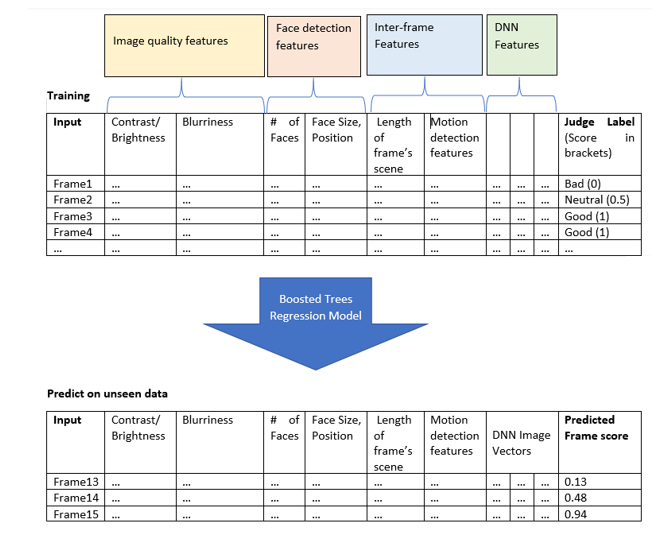
Here’s how we created a machine-learning pipeline for selecting the primary thumbnail of any video. First and foremost, you need labelled data, and lots of it. To teach our machines some examples of good and bad thumbnails, we randomly sample 30 frames (frame = still image) from the video and show it to our judges. The judges evaluate these frames using a subjective evaluation that considers attributes such as image quality, representativeness, attractiveness, etc. and assign each frame a label based on its quality as Good, Neutral, Bad (scored as 1,0.5,0). Point to note – our training data is not query specific, i.e. the judges are evaluating the thumbnail in isolation, and not in the context of the query. This training data, along with a host of features from these images (more on that in a bit) are used to train a boosted trees regression model that tries to predict the label on an unseen frame based on its features. The boosted trees model outputs a score between 0 and 1 that helps us decide the best frame that can be used as a primary thumbnail for the video.
What were the features that turned out to be useful in selecting a good thumbnail? As it turned out, core image quality features turned out to be very useful (i.e. features like the level of contrast, the blurriness, the level of noise, etc.). We also used sophisticated features powered by face-detection (# of faces detected, face size and position relative to the frame, etc). Also used were motion detection features and frame difference/frame similarity features. Visually similar and temporally co-located frames are grouped together into video sequences called scenes, and the scene length of the corresponding frame is also used as a feature – this turns out to be helpful in deciding whether the selected thumbnail is a good one. Finally, we also use deep neural networks (DNN) to train high-dimensional image vectors on the image quality labels and these vectors are used to capture the quality of the frame layout (factors like the zoom level [absence of extreme close ups and extreme zoom outs etc.]). The frame with highest predicted frame score is selected as the primary thumbnail to be shown to the user.
Here is a visual schematic:
Step Two: Selecting the remaining thumbnails for the video summary
The next step is to create a four-thumbnail set that provides a good representative summary of the video. A key requirement is comprehensiveness and it brings in many technical challenges. For instance, we could have simply taken the four frames with the highest scores from previous step and created a summary. But that won’t work in most cases because there’s a high chance that the four top-scored frames are from the exact same scene, and they don’t do a good job of summarizing the whole video. There are other problems too - from a computational cost point of view, it is impractical to evaluate all possible sets of four-frame candidates. Thirdly, it’s hard to collect training data from users about the four frames that best summarize a video, because, it is hard for users to select the 4 best frames from a video having thousands of frames. Here’s how we handle each of these problems.
To deal with the comprehensiveness, we introduce a similarity factor in the objective function. The new objective function for the expanded thumbnail set not only tries to maximize the total image quality score, but also adds an additional tuning parameter for similarity. The weight for this parameter is trained from user’s labelled data (more on that below). The similarity factor currently has a negative weight (i.e. a set of 4 high quality frames in which the frames are mutually diverse, will generally be considered a better summary than a corresponding set where the frames are similar).
We deal with computational complexity by formulating the problem as a greedy optimization problem. As stated before, it’s not possible to evaluate every possible combination of 4-frame summaries. Moreover, the best combination of 4 frames need not contain the primary thumbnail (it’s possible that the best combination excludes the primary thumbnail). But since we’ve already taken great pains to select the primary thumbnail, it can greatly simplify our task if we use this as a starting point to select just three more thumbnails that help maximize the total score. That’s greedy optimization.
Here’s how we generate training data for learning the weights for similarity and other features. We show judges a set of 4 frames on LHS and RHS (these frames are randomly selected from the video) and ask them to do a side-by-side judgment (label as “leftbetter”, “rightbetter”, or “equal”). This training data is then used to derive the thumbnail-set model by training the new objective function (total image quality score and similarity) for the 4-frame set. As it turned out, based on the training data, the weight for similarity is negative (i.e. in general, more visually diverse frame-sets lead to better summaries). That’s how we select the 4-thumbnail set.

Here are some examples that show the improved performance our new model over baseline methods available in static video summarization.



Outcome: Creating a playable preview video from 4 thumbnails
Of course with all the technical wizardry we can’t forget our main objective which is to generate a playable video clip from these 4 thumbnails to help our users better locate web videos. We do that by extracting a small clip around each of these four frames. How we find the boundaries to snip etc. is probably the subject of another blog. The result of all of this is a Smart Preview that helps users know what’s in the video. This means all of us can spend less time searching and more time watching the videos we want. As with earlier features like coding answer, the goal is to build an intelligent search engine and save users’ time. Try it out on our video vertical.
