
As the saying goes, “a picture is worth a thousand words”. Pictures help us to capture our favorite memories and experience the world around us. But that memory or experience is degraded significantly when we encounter a low quality image. Maybe the photo was taken with an old camera, the dimensions of the image are too small, or the file was overly compressed at some point. We can all probably think of a time when we had the perfect image - a prized portrait of a family member to be framed or the best screenshot to illustrate your point in a presentation - but could not use it because the quality was too low. Using the power of Deep Learning, the Microsoft Turing team has built a new model to help in these scenarios.

 Original
Original Turing-ISR
Turing-ISR Original
Original Turing-ISR
Turing-ISRWe call this model Turing Image Super-Resolution (T-ISR), another addition to the Microsoft Turing family of image and language models powering various AI experiences across the company. At Microsoft we have been steadily rolling out this capability in a variety of our products and have seen a strong positive response from our users:
- In Bing Maps, we are using the model to improve the quality of our aerial imagery for our users around the world! The model is robust to all types of terrain and in our side-by-side tests with users, the super-resolved aerial images are preferred over the original imagery 98% of the time. We have rolled out the model to most of the world’s land area, benefiting the vast majority of our users across the globe. In addition, we are able to bring this experience not only to our Bing Maps users, but also to our customers on Azure who leverage Azure Maps satellite imagery for their own products and services.
- In Microsoft Edge, we are starting to roll out the model to allow users to enhance the images they see on the web with the goal of turning Microsoft Edge into the best browser for viewing images on the web. We have seen early promising feedback from our users and are continuing to improve the experience as it scales to serve all images on the internet!
.png?lang=en-US) Original
Original.png?lang=en-US) Turing-ISR
Turing-ISR Original
Original Turing-ISR
Turing-ISR Original
Original Turing-ISR
Turing-ISR Original
Original Turing-ISR
Turing-ISR Original
Original Turing-ISR
Turing-ISRModel Details
In our exploration of the super-resolution problem space, there were four major findings that played a key role in the development of our state-of-the-art (SOTA) model:
- Human eyes as the north star: The metrics widely used in industry and academic models, PSNR and SSIM, were not always aligned with the perception and preference of the human eye and also required a ground truth image to be computed. In response, we built a side-by-side evaluation tool that measured the preferences of human judges and we used this tool as the north star metric to build and improve our model.
- Noise modeling: In the first version of our training recipe, we created low-resolution and high-resolution pairs for training by simply taking a large number of high-quality images and downscaling them. We then trained the model with the downscaled image as input and an objective of recovering the ground truth as closely as possible. While this approach produced good results in many cases, we found that it was not robust enough to handle many of the “true” low-resolution images we were testing with, like ones coming from the web or old cameras. We found that by randomly applying distortions on our training input images such as blurring, compression, and gaussian noise, our model learned how to recover details for a much wider set of low-quality images.
- Perceptual and GAN loss: Like the first finding, we found that optimizing our models solely using pixel loss between the output images and ground truth images was not enough to produce the optimal output that aligned with a human eye’s perception. In response, we also introduced perceptual and GAN loss and tuned an optimal weighted combination of the three losses as an objective function.
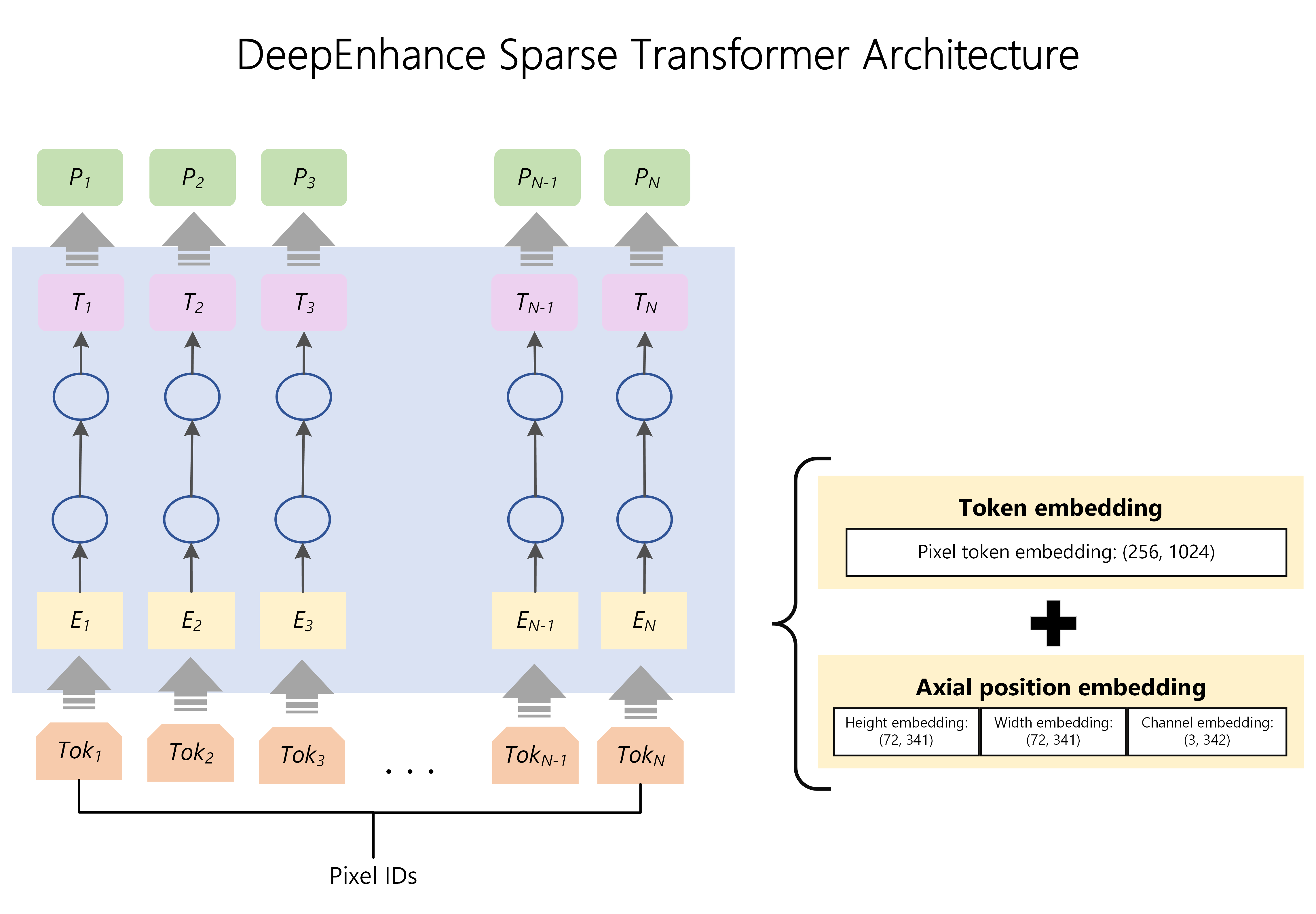
- Transformers for vision: When we began working on super-resolution, we saw that most approaches were still using CNN architectures. Given the Microsoft Turing team’s expertise and success applying transformers in large, language models and our recent use of transformers in our multi-modal Turing Bletchley model, we experimented with transformers and found it had some compelling advantages (along with some disadvantages). Ultimately, we incorporated the positive aspects of both architectures by breaking the problem space into two stages: 1) Enhance and 2) Zoom.
DeepEnhance – Cleaning and Enhancing Images
When testing with very noisy images like highly compressed photos or aerial photos taken from long range satellites, we found that transformer-based models did a very good job at “cleaning” up the noise tailored to what was in the image. For example, noise around a person’s face was handled differently than the noise on a highly textured photo of a forest. We believe this is because of the large datasets we trained on and the superior long-range memory capabilities of transformer architectures. So as a first step, we use a sparse transformer which we scaled up to support extremely large sequence lengths (to adequately process the large context of an image) to “enhance” the image. The result is a cleaner, crisper, and much more attractive output image whose size is the same as the input. In some product scenarios, a larger image is not needed, so in those cases we stop here.
 Original
Original Turing-ISR
Turing-ISR Original
Original Turing-ISR
Turing-ISRDeepZoom – Scaling up Images
In other product scenarios, we want an image that is larger than the original image; we want to “zoom” the image. While there are many methods to zoom an image, the most commonly used method is bicubic interpolation. When you drag the corner of the image on your favorite image editing software, you are likely using bicubic interpolation. In bicubic interpolation, pixels are inferred based on the surrounding pixels. The result is usually a grainy image missing a large amount of detail that gets worse the larger the scaling factor is. Rather than naively interpolating pixels solely based on the surrounding pixels, we trained a 200-layer CNN to learn the best way to recover “lost” pixel detail. The result is a model that knows the best way to recover pixels for the specific types and scenes of an image.
.png?lang=en-US) T-ISR DeepZoom CNN
T-ISR DeepZoom CNN



Generalization Ability
The T-ISR model was trained on a massive and diverse amount of data across several different tasks. Because of this, the same T-ISR model can be shipped in Bing Maps, Microsoft Edge and potentially other experiences as well. In fact, this diversity in domains helped to push fundamental model improvements. For example, improvements we made to the training recipe to handle specific challenges in the heavily forested rural areas of our satellite images also helped to improve the quality of our model output for “natural” images, like ones of people, animals, and buildings. We believe this approach is one of the main reasons our model performs so well on traditional benchmarks.
Optimization and Shipping
To ship super-resolution at scale to our users, there were several optimizations we needed to make the model cost-efficient. The first set of optimizations were all around reducing model size and latency. As you can see from the graph below, after quantization, using ONNX Runtime (ORT), and model pruning with the help of the Microsoft DeepSpeed team we were able to reduce the model latency by 16x.

In addition to core model optimizations, we also did some further engineering optimizations to enable the experience to scale. For shipping in Bing Maps, while we had massive amounts of data to process, we had the benefit of being able to process this data offline as large batch jobs. Bing’s Deep Learning Inferencing Service (DLIS) enabled us to exploit this fact and harvest idle GPU time to run our jobs: a win-win for the platform and our users! For shipping in Microsoft Edge, we’re using CDNs so that the same image does not need to be processed repeatedly, cutting down latency and processing load significantly.
Responsible AI
From our work with large language models, the Microsoft Turing team is aware of the issues that plague large, generalizable deep learning models. We, like the rest of the AI community, have invested and continue to invest in efforts to study and prevent these harms and these efforts extend to the T-ISR model.
In a world of deepfakes and other similar harms, we are cognizant of the challenges posed in the image space. While shipping T-ISR in production scenarios, we have carefully followed the measures outlined by the Microsoft Responsible AI principles to mitigate and minimize potential harm to users. Those principles emphasize that fairness, reliability and safety, privacy and security, inclusiveness, transparency, and accountability be considered as the key cornerstones of a responsible and trustworthy approach to development and use of AI.
Future
As mentioned, you can currently find T-ISR shipped in the Aerial View of Bing Maps around the world! And T-ISR in Microsoft Edge is currently shipped in Edge Canary and we will continue to roll this out to more and more users in the coming months. The ultimate mission for the Turing Super-Resolution effort is to turn any application where people view, consume or create media into an “HD” experience. We are closely working with key teams across Microsoft to explore how to achieve that vision in more places and on more devices.
