
In part 2 of our bingbot series Principal Software Engineering Manager of the crawl team Cheng Lu shares one example of how we’ve optimized our processes to maximize crawl efficiency for large web sites whose content remains static, or unchanging.
Keeping Indexed Content Current and limiting crawling on content that has changed
When most people conduct a search they typically are looking for the most recent content published; however, the search engine results may link to webpages that were published days ago to years ago. This is a challenge, especially when searchers are wanting to keep up with breaking news and the latest trends by accessing the most up-to-date content online. The internet and search index are full of ghosts of yester-years past, that are often resurrected by the power of search engines. For instance, I was able to retrieve the Microsoft 1996 annual report. Interesting, yes, especially if I need to do a historical report, but if I'm looking for the current annual investment report, it is not so useful. The crawler also needs to have discovered, crawled and indexed the latest Microsoft annual report in order for me to discover it when I do a search.
The challenge for bingbot is that it can't fetch a web page only once. Once a page is published, the search engine must fetch the page regularly to verify that the content has not been updated and that the page is not a dead link. Defining when to fetch the web page next is the hard problem we are looking to optimize with your help.
Case Study: Cornell University Library - A great source of knowledge with many static, unchanging web pages
One challenge that we are trying to address is how often should bingbot crawl a site to fetch the content. The answer depends on the frequency of which the content is edited and updated.
The Cornell University Library empowers Cornell's research and learning community with deep expertise, innovative services, and outstanding collections strengthened by strategic partnerships. Their web site https://arxiv.org/ is a mine of relevant information and it contains millions of web pages on a range of topic from Physics, to Science to Economics. Not only do they have millions of webpages and PDF files related to computer science, they even have content related to crawling and indexing websites.
Identifying patterns to allow bingbot to reduce crawl frequency
While new web pages may be posted daily, and some pages are updated on a regular basis, most of the content within the Cornell University Library is not edited for month and even years. The content is by in large static and unedited. By unedited, I mean that the HTML may change a little, for example {copyright 2018} will {become 2019} on January 1st, the CSS and style sheet may change a little; however such changes are not relevant for updating the indexed content within Bing. The content of the page is still the same. Additionally, only few articles are deleted every year. Their library index increases in size with new and updated research, without substantially changing the content of the historically indexed research.
Reviewing our crawling data, we discovered that bingbot was over-crawling the content and we were using more resources then necessary to check and re-check that the historical pages maintained static in nature. What we learned was that we could optimize our system to avoid fetching the same content over and over, and instead check periodically for major changes. This resulted in about 40% crawl saving on this site!
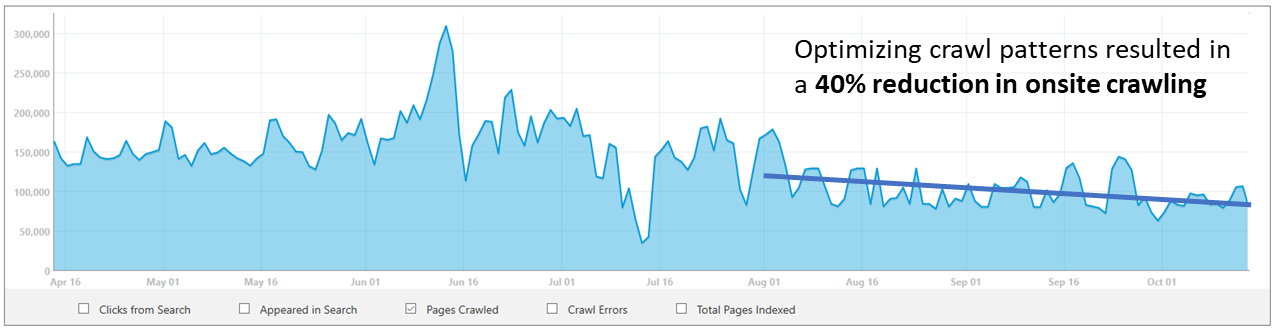
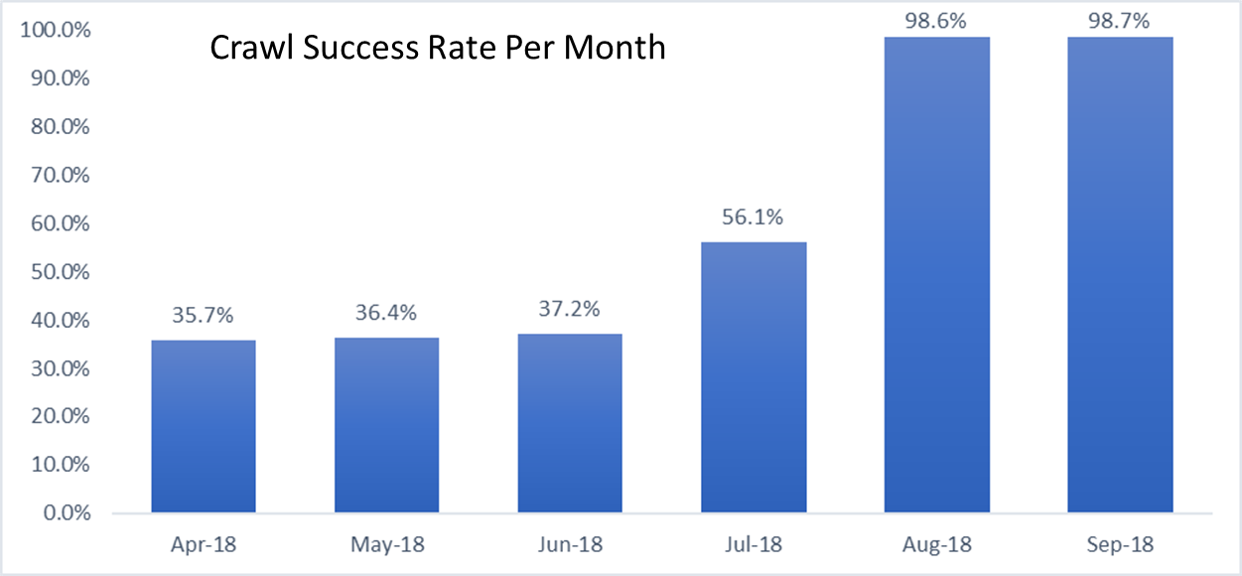
While our work in identified patterns for largely static content identified an opportunity to reduce crawling for this “class” of websites (slow and rarely changing content) and in the following posts we’ll share more learnings.
Our work with improving crawler efficiency is not done yet, and we’ve got a lot of opportunity ahead of us to continue to improve our crawler’s efficiency and abilities across the hundreds of different types of data that are used to evaluate our crawler scheduling algorithms. The next step is to continue to identify patterns that apply to a multitude of websites, so we can scale our efforts and be more efficient with crawling everywhere.
Stay tuned! Next in this series of posts related to bingbot and our crawler, we’ll provide visibility on the main criteria involved in defining bingbots Crawl Quota and Crawl Frequency per site. I hope you are still looking forward to learning more about how we improve crawl efficiency and as always, we look forward to seeing your comments and feedback.
Thanks!
Cheng Lu
Principal Software Engineering Manager
Microsoft - Bing
Fabrice Canel
Principal Program Manager
Microsoft - Bing