
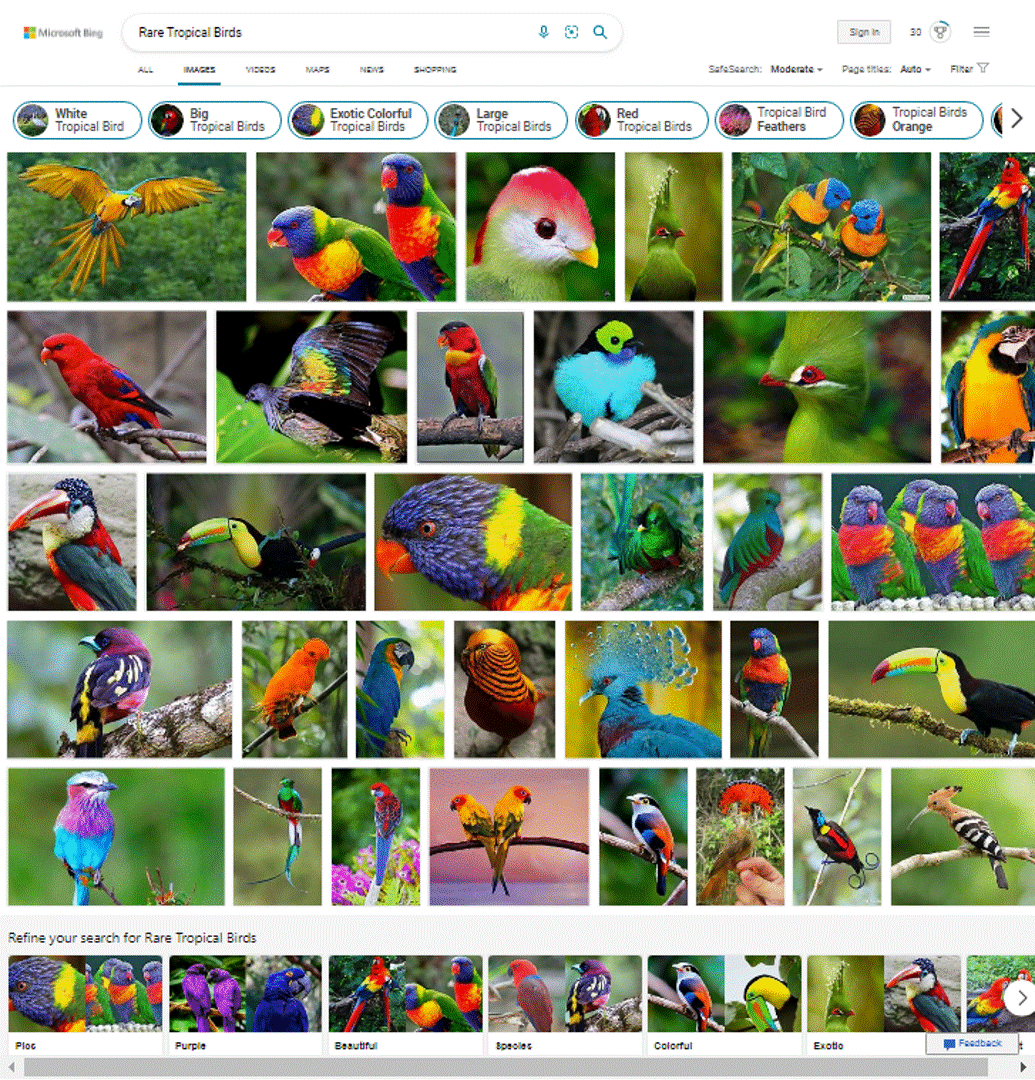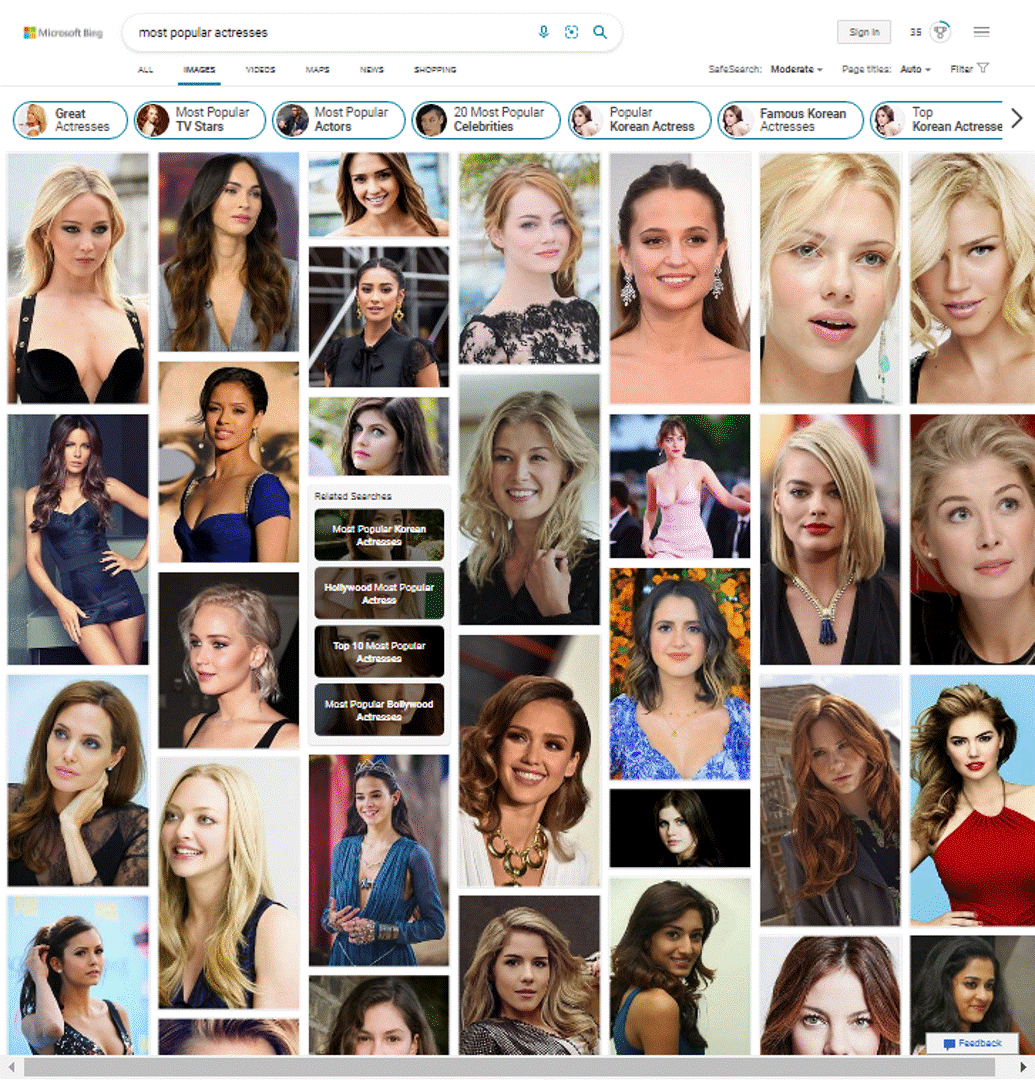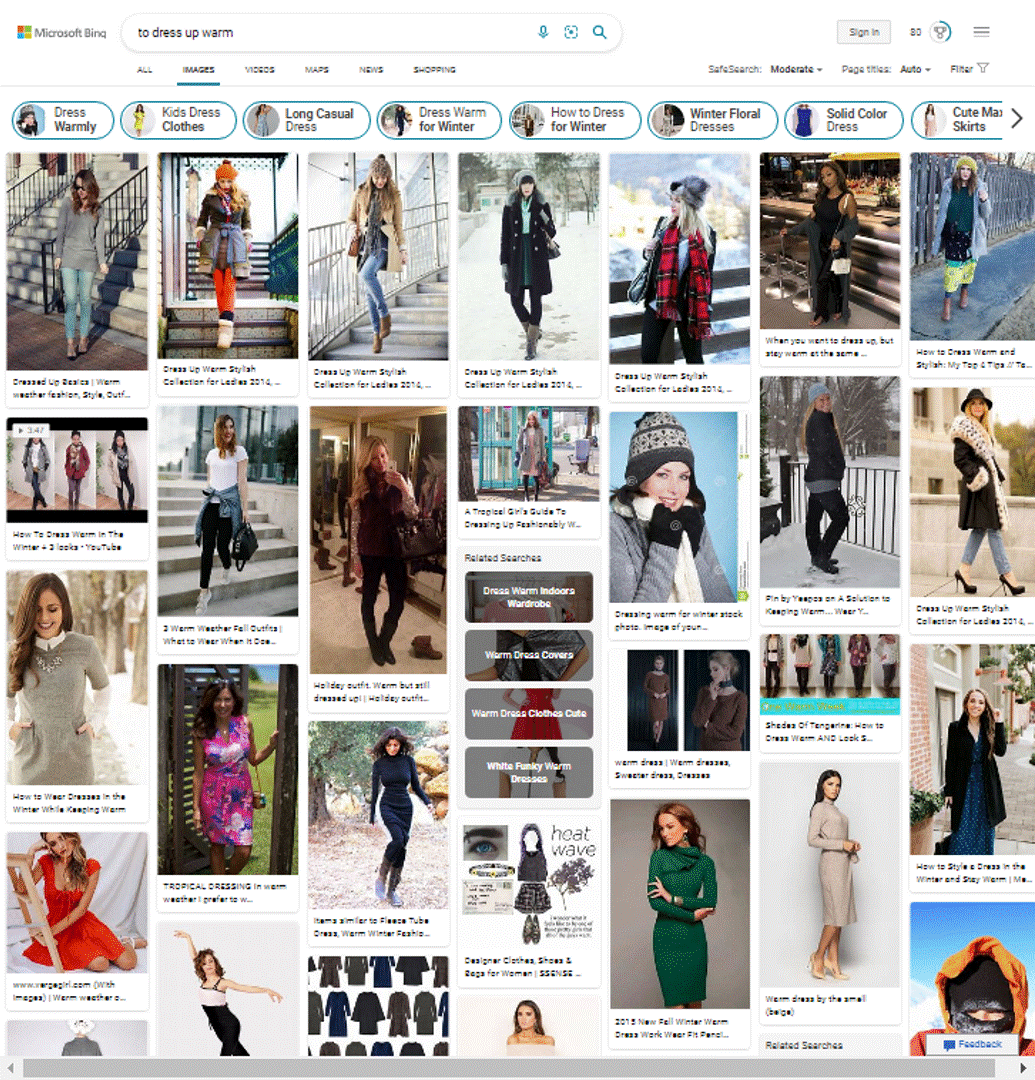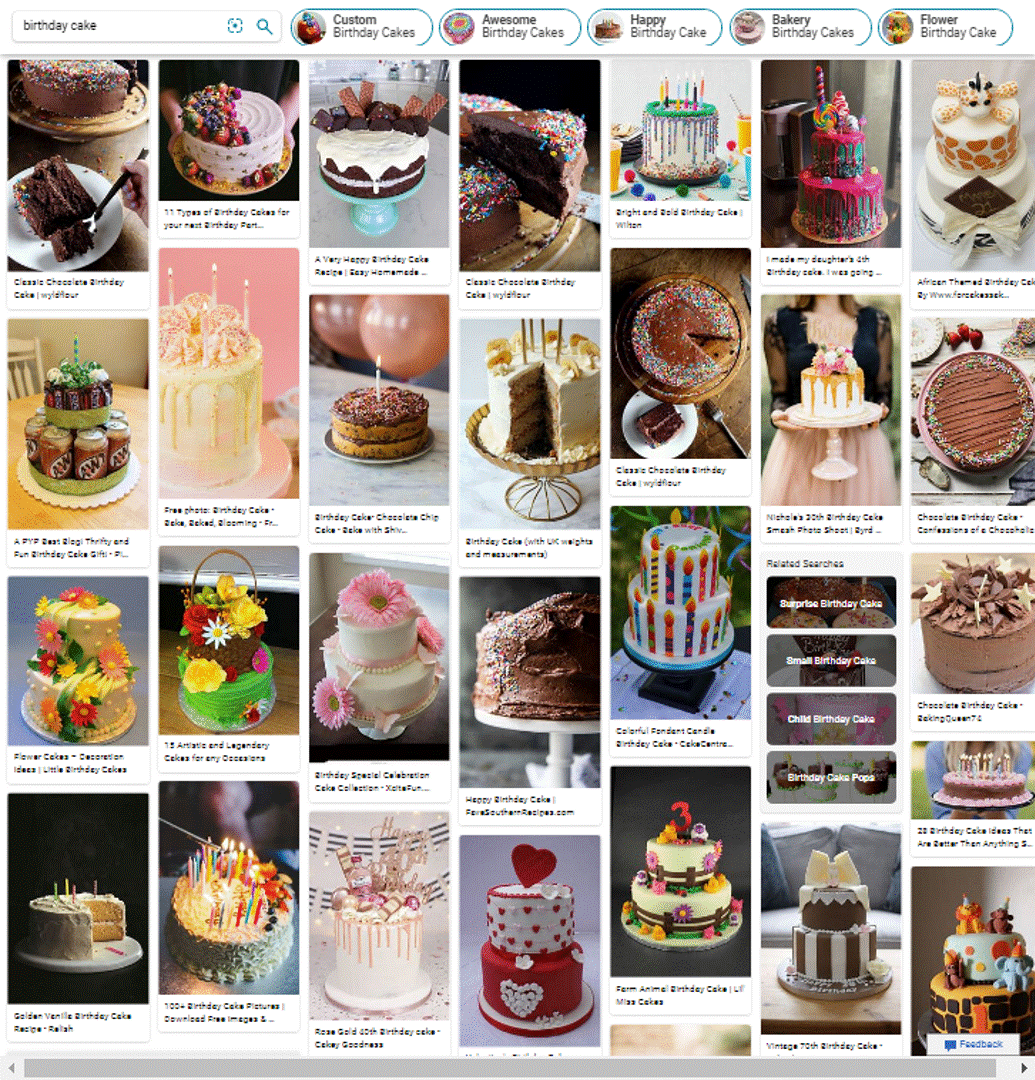
Aesthetic Model V3 results on Bing Image Search
Enhancing Image quality is an essential yet very challenging computer vision task. Ever since our phones became cameras, always with us, ready to create rich multimedia content, there's been a tremendous growth in online photos. This places great demands on search engines to organize, manage, recommend, and offer high-quality multimedia results to users. The search engines must make sure that the search results are not only relevant but also fresh, beautiful, and of high-resolution.
While object categorization and detection have reached human-level accuracy, determining the high quality of an image automatically is far from a solved problem. Aesthetics and high quality are crucial in various multimedia applications, including image retrieval in Microsoft Bing, Google, Pinterest, and others. Users expect rich, high quality multimedia results from a search engine without jeopardizing relevance.
To improve the image quality in our search and multimedia products, we released the updated version (V3) of the Aesthetic model. The V3 model improves (details below) upon the V2 model, in several ways and helps Bing Search Results come to life with relevant, high-quality, inspiring, and enticing images. You can already see the best-looking images as selected by our Aesthetic model in several places in Bing. In addition, there are new immersive user experiences in the pipeline – stay tuned. We will share more details in future posts.
Bing uses deep learning models using state-of-the-art pretrained encoder [1] , web scale data and multi-task training objectives to provide stunning and aesthetically pleasing photos. Bing Multimedia team aims to empower customers with media-rich experiences, and our research on Image Aesthetic AI models supports our goal. Aligning with our mission, in 2019, we introduced a unique framework for ranking image aesthetics by training a paired deep network on a huge dataset of side-by-side multi-labeled image pairings. By obtaining a relative ranking between two photos rather than just assigning an absolute score or evaluating any established image feature, we provided a more straightforward and accurate assessment.
With our V2 Model, we augmented a deep attractiveness rank net (DARN), a hybrid of a deep convolutional neural network and a rank net, with human tagging (crowdsourced) to directly learn the mean and variance of each image's attractiveness score (DARN-V2) [2]. We demonstrated that adding this considerably increased the aesthetics of search results and outperformed other models on our side-by-side online test data and another public aesthetic data set.
In July of this year, we released a new version of our Aesthetic model – V3 which improves on a few limitations of the V2 Model. We learned from the V2 model that majority judge voting does not fully capture judges’ sentiment since it ignores minority judge ratings. As a result, we established the KL Divergence as a metric for model accuracy and approached the problem as regression rather than a classification one. KL Divergence, in particular, takes preference diversity into account. It encourages the model to give a larger score gap if one side is obviously more aesthetically pleasing than the other side and a smaller score gap if two images are of similar quality. Compared with the V2's SBS (side-by-side) accuracy, KL Divergence metric is better aligned with our ranker usage scenario.
As a result, the new Aesthetic model more accurately captures preference variation across different judges during the training stage and generates Aesthetic ratings that are more consistent with general preference during inference.
Additionally, the V3 model is size-aware. In the V2 model, the images were resized into a uniform size before training, which introduced distortion in images in the training dataset. The V3 model is size-informed, as size is a critical feature in determining an image's aesthetics. The original-size signal allows the model to compensate for image degradation and distortion suffered by the V2 model. Additionally, we train our model to assign a higher score to a larger image if the images are identical but of different sizes. The V3 model also considers composition, subjects, lightness, contrast, exposure, focus, saturation, and resolution.

Example preference differences in image pairs under V2 and V3 models
The V3 model was evaluated both with in-house data from Bing and Opensource Aesthetic datasets, CHUKPQ [3] and AVA [4], and it generalized very well on these unseen Aesthetic datasets.
Compared to the V2, the V3 model has a better aesthetic taste that is more in line with human perception. We used the KL divergence to measure the distance between Bernoulli distributions output by model and the aggregated opinion of multiple judges on an aesthetics side-by-side (SBS) test set of 53K image pairs. It was discovered that V3 reduced the distance by 48%. Similarly, V3 improves SBS accuracy by 10% on the public aesthetic dataset CUHKPQ. Furthermore, V3 aligns better with the relevance metrics calibration, with a 36% higher correlation with human judgment.
| Datasets | Source | Size (#Images | #Images Pairs | SBS Accuracy (%: V2 | V3) |
| AVA | Photography Forum | 256K | 271K | 79.79 | 83.04 |
| CUHKPQ | Photography Forum + Students’ Pictures | 30K | 120K | 67.54 | 77.20 |
| Aesthetic SBS Set | DCG Calibration Set | |
| V3 | 1.0033 | 0.158 |
| V2 | 1.9151 | 0.116 |
Take a look yourself how the Image Aesthetic model V3 performs on bing.com/images for your search query and in Visual Search.
Share your experiences and provide feedback so that we can continue to improve our models.
- Jie Chen, Yiran Shen, Ashish Jaiman, and The Bing Multimedia team
References
[1] Microsoft Vision Model ResNet-50 combines web-scale data and multi-task learning to achieve state of the art - Microsoft Research
[2] An Universal Image Attractiveness Ranking Framework
[3] CUHKPQ is another Aesthetic dataset with 17,613 photos. It is a mixture of high-quality images derived from photographic communities and low-quality images provided by university students.
[4] AVA: A Large-Scale Database for Aesthetic Visual Analysis - AVA is a large-scale database for conducting Aesthetic Visual Analysis (AVA). It contains over 250,000 images collected from the online community of photography amateurs at www.dpchallenge.com. The number of votes under each image indicates how aesthetically pleasing it is.
