
We released Bling Fire Tokenizer to open source a year ago, to great community interest. We also got feedback and feature asks from you that we’ve addressed since then.
We’ve since added support for the BERT-style tokenizers with normalization and sub-token extraction. We provide precompiled tokenization models for BERT base/large, BERT base/large cased, BERT Chinese, Bert Multilingual Cased. As well as added instructions to create your own tokenization models here and here.
In terms of speed, we’ve now measured how Bling Fire Tokenizer compares with the current BERT style tokenizers: the original WordPiece BERT tokenizer and Hugging Face tokenizer. Using the BERT Base Uncased tokenization task, we’ve ran the original BERT tokenizer, the latest Hugging Face tokenizer and Bling Fire v0.0.13 with the following results:
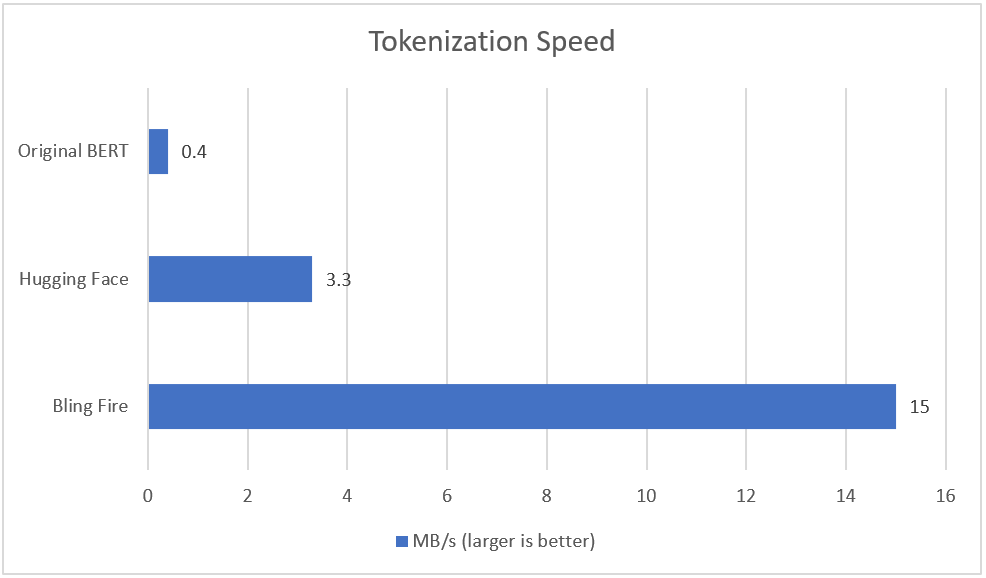
As you can see Bling Fire is much faster than existing tokenizers for BERT based models. You can find the details of the benchmark here.
Bling Fire provides state of the art latency and is available for Windows, Linux and Mac OS X platforms. You can get access to the library and find out more details at: https://github.com/Microsoft/BlingFire. To reach out to the team with questions or comments, connect with us on Stack Overflow.
- Bling Web Data Team
