
At Bing, AI is the foundation of our services and experiences. If you have ever been involved in any machine learning or AI project you know that frequently the key to success is good training data (a set of labeled examples that helps train the algorithm). Getting enough high-quality training data is often the most challenging piece of building an AI-based service. Typically, data labeled by humans is of high quality (has relatively few mistakes) but comes at high cost - both in terms of money and time. On the other hand, automatic approaches allow for cheaper data generation in large quantities but result in more labeling errors ('label noise'). In this blog we describe a new, creative way of combining human based and automatic labeling to generate large quantities of much lower-noise training data for visual tasks than was possible ever before.
This new technology developed here at Microsoft and subject of today’s post has been at the foundation of the quality you have seen in various Bing multimedia services. To share the discoveries and empower a broader AI community to build better experiences for all of us, we will also present this technique at this year's Computer Vision and Pattern Recognition Conference (CVPR) taking place in Salt Lake City between June 19th and 21st .
Background
To explain the challenge in a bit more detail, let's use an example: imagine that we are trying to build an image classification system that could determine what category of object is shown in a given image. We want to be able to detect a number of such categories. For instance, we may want to detect different types of foods visible in the image. To build it, we need a lot of example images of food with corresponding category names. Once we train the model on our training data, we will be able to present the system with an image and it would produce a category corresponding to the type of food detected in the image.
We could try to use human labeling to create our training data: take example pictures of food for each of our categories and use that. It would work but it would also be very expensive considering that we may need thousands if not millions of examples: each type of food can be portrayed in multitude of different ways, and there are hundreds if not thousands of different food categories.
The typical approach to solving this problem would be to 'scrape' an existing search engine. What this means is that we would first collect a list of names of food categories we want to be able to identify in the images, possibly with their synonyms and variations. Then we would issue each such name as a query to an image search engine and collect resulting images, expecting that they would in fact portray food of the category we used in the query. Thus, if we wanted to be able to identify tuna in our images we could issue queries such as 'tuna', ‘tuna dishes’, or 'maguro' (tuna in Japanese), and collect corresponding images for training. We would do the same for any other category we wish to detect. This process can be automated so we can easily generate a lot of data for many categories.
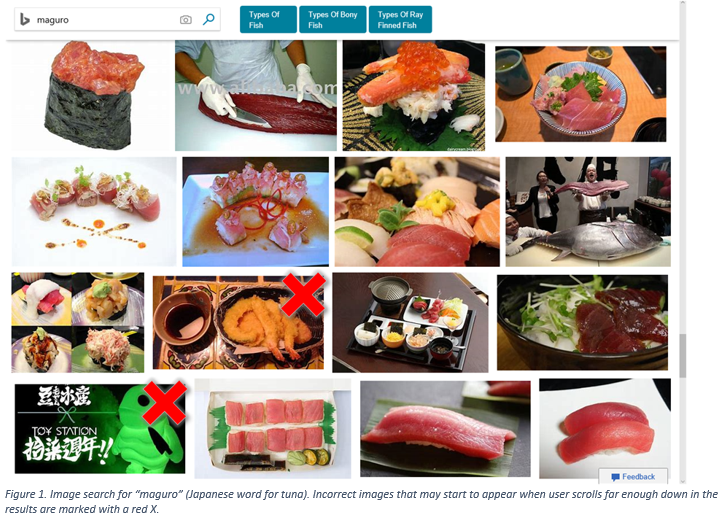
The challenge
As you can see above, search engines are unfortunately not perfect – no matter which engine you use, if you scroll down far enough in the results you will start seeing some mistakes. Mistakes in the training data mislead our classifier during the training process. This in turn leads to inferior performance of the final system. So how can we correct those mistakes - and avoid having to look through all the scraped images to find the errors? One approach that is popular in the community would be to train another model ('cleaning model') specifically to find images which don't match their category (are 'mis-labeled'). The diagram below shows how such a cleaning model would be used.
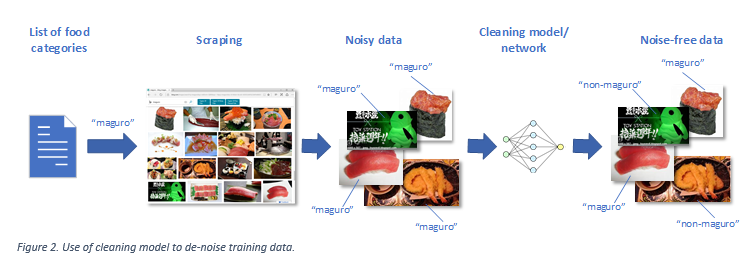
This can be done but we would need some number of correctly and incorrectly labeled examples for each food category, so that during training of the 'cleaning model' it can learn how to tell for each category what a correctly and incorrectly labeled image looks like so that it can later spot the errors. That is all doable if we have relatively few categories. But it becomes very problematic if we want to detect thousands, hundreds of thousands, or even more categories. Just labeling a few examples for each category manually would again be prohibitively expensive.
While AI scientists have come up with specialized 'outlier detection models' that could help here, they usually either require labeling all categories, which presents the scalability problem described above, or they require no labeling at all but then suffer from poor accuracy. Preferably we would like to have a bit of both: infuse the system with some amount human intelligence in the form of labels while controlling the cost, and use it to improve quality of an otherwise automatic cleaning model. Can this be done? That's exactly where our new approach comes in!
The solution
In our 'dream' solution we would like to have a small subset of labels generated by the web scraping process (described earlier) to be verified by humans, but not necessarily enough to cover all categories (also referred to as ‘classes’) or all possible types of errors. We would then like the system to learn from this data to detect labeling flaws for many other types of categories, specifically those that we did not have labeled examples from. With recent advances in AI it is now possible.
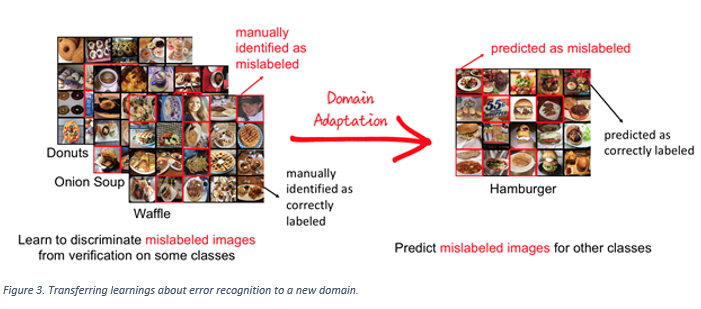
The crux of the solution is to teach the AI model what a typical error looks like for a few example categories (such as 'Donuts', 'Onion Soup', 'Waffle' in the picture below) and then use techniques such as 'transfer learning' and ‘domain adaptation’ to get the model to intelligently use those 'learnings' in all the other categories where human labeled examples are not available ('Hamburger').
The way this is realized is that behind the scenes, while system is being trained, one part of the model effectively learns how to automatically ‘select’ (assign weights for) images best representing each of the categories, and map them to a single high dimensional vector. This will form 'class embedding vector' - a vector representing given category. This part of the network will be fed noisy, web-scraped training data during training.
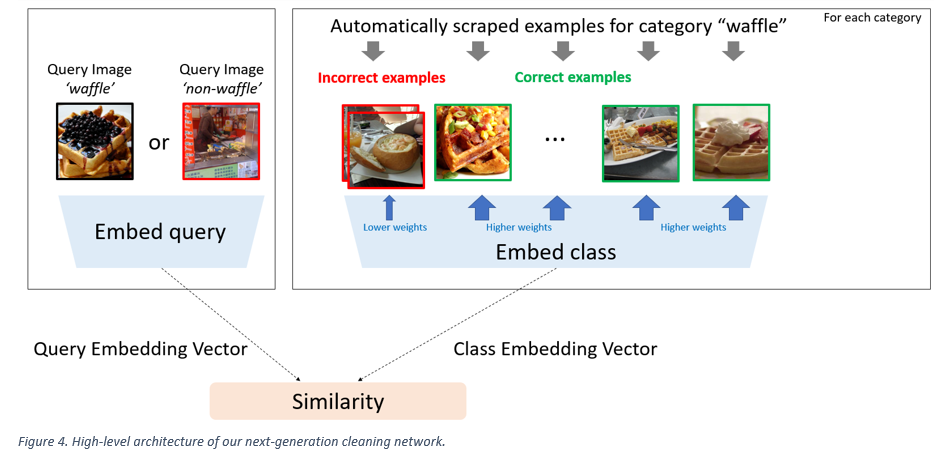
At the same time, another part of the model is learning to embed each example image (call it 'query image') into the same high dimensional space. Both parts of the network are trained at the same time ('joint embedding framework') and the training process is further constrained in such a way as to nudge the system to make the class embedding vector and the query image vector similar to one another if the image is in fact a member of the category, and further apart if it is not.
Thanks to this arrangement, the system can now learn that some of the noisy, web scraped examples that it was fed are probably incorrect and shouldn't be trusted. In the process it also learns general patterns about the nature and best ways of finding representative images for each category, that turn out to continue to work well on categories even where no human verified labels were present!
We realize that it may take a moment to wrap your head around what exactly is happening here, but such is the nature and beauty of modern AI today. Amazingly, the system works very well, and it learns to quite reliably identify correct and incorrect labels in all categories whether there were any human verified labels available or not.
Closing thoughts
The approach discussed in this post is already proving very effective in producing clean training data for image-related tasks. We believe it will be equally useful when applied to video, text, or speech. Our teams are already looking into it. Continue to check our blog for new developments!
If you want a more in-depth look at this technology, check out our Microsoft Research blog post here or read the corresponding paper for all the technical details, which we'll be presenting soon at CVPR.
In the meantime, know that every time you use Bing you are consuming the fruits of these amazing technologies. And if you are also an AI fan, just go ahead and try out some of the described techniques to generate quality training data for your own projects!
Happy Training!
The Bing Team